PinnedPaddle your own CanoeDeep down the heart I realise this phrase ‘Paddle your own canoe’ is so true. In this one life we have been given with pretty much…Mar 2, 2021Mar 2, 2021
Usecase#4: Reverse-Explode Functionality using Spark-scalaRequirement is to reverse the Explode operation to convert the string into array values on Spark Dataframe.Jan 3, 2022Jan 3, 2022
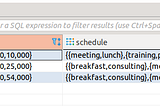
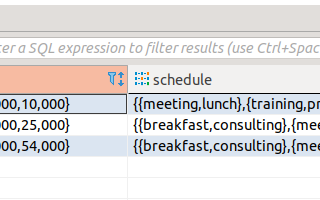
Usecase#3 on Spark-scalaUsecase: Source table is on PostgreSQL(any JDBC related Databases) having data as multidimensional array types. Requirement is to read the…Sep 28, 20211Sep 28, 20211
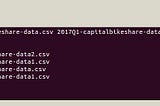
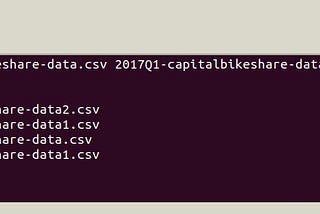
Usecase#2#Spark(Get a file of size in GB without downloading)Usecase: Get a file say csv of size 5GB–10GB and process it in Spark.Jul 22, 2021Jul 22, 2021
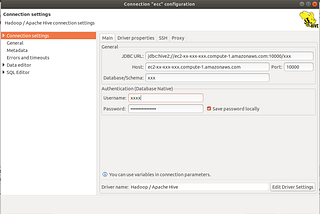
Hive connection (Remote Server) to Spark-scala (as sink/source) through JDBC (non Kerberos)If there is a requirement to connect to Hive installed on remote server to a Spark application(written in scala and running on separate AWS…May 28, 2021May 28, 2021
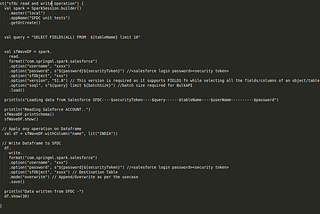
SFDC(Salesforce.com) Spark connector-(as sink/source)-scalaIf there is a usecase to add SFDC as a connector to a Spark application (written in scala), then here you can refer below code (Test.scala)…May 28, 2021May 28, 2021
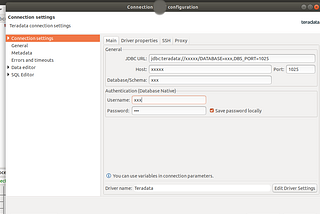
Teradata connector-Spark-Scala(sink/source)If there is a usecase to add Teradata as a connector to a Spark application (written in scala), then here you can refer below code…May 28, 2021May 28, 2021
Usecase#1 on SparkScalaProblem Statement: There is a source DB2 and sink as MongoDb where you are reading data from DB2 and writing it to MongoDb. But while…May 13, 2021May 13, 2021
Google Big Query connector-Spark-Scala(sink/source)If there is a usecase to add Big Query connector(using GCP) to a Spark application (written in scala), then here you can refer below code…May 12, 2021May 12, 2021
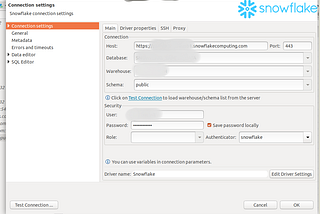
Snowflake Connector with Apache Spark(scala)- Source-Sink ConnectivityIf there is a requirement to add Cloud warehouse Snowflake connector to a Spark application written in scala, then here you can refer…Apr 25, 2021Apr 25, 2021